
Teaching to the Test: How Benchmark Gaming Could Influence AI Progress
This article explores the rapid evolution of AI benchmarking and how the pressure to engineer evaluations risks distorting true progress toward advanced machine intelligence.


In 2000, George W. Bush came into the Oval Office on the wings of education reform, his Texas standardized testing policies a beacon of promise. "We're gonna spend more money, more resources," he declared, "but they'll be directed at methods that work. Not feel-good methods. Not sound-good methods. But methods that actually work."
Bush's solution? The No Child Left Behind Act (NCLB) – a bipartisan effort to raise the bar through rigorous standardized testing. On paper, it seemed a panacea for the chronic disparities plaguing America's schools. Quantifiable metrics would finally hold educators accountable and shine a light on underperforming districts.
However, the financial implications of NCLB created a perverse incentive. Across the nation, curricula contorted to favor test preparation over comprehensive education. Teachers triage-taught, funneling attention toward students teetering on the pass/fail line while high-achievers and those with significant learning needs fell by the wayside. Subjects like art and music – untested and thus undervalued – withered on the vine.
In the shadows of good intentions, a new reality took shape: One where "teaching to the test" became an open secret, data-driven accountability its own paradox. The road to equity, it seemed, had muddied into a numbers game riddled with unintended consequences.

In today's high-stakes arena of large language model development, an eerily familiar pattern is emerging – one that echoes the unintended consequences of NCLB. As new models roll off the assembly line in rapid succession, each one jockeys to plant its flag atop the latest benchmarks. Records are toppled with regularity amid a flurry of breathless announcements touting new performance milestones.
But are these achievements truly reflective of groundbreaking AI capabilities, or merely the result of excessive benchmark specialization akin to "teaching to the test"?
In this article, we'll trace the history of AI benchmarking – from its origins driving innovation to its present-day role as a double-edged sword. As the field barrels towards new frontiers, guided by an evolving constellation of metrics, we must grapple with the limitations of our current evaluation paradigms.
Related:

Benchmarking's Catalytic Role
For decades, the field of artificial intelligence has relied on benchmarks - carefully curated datasets and challenges designed to quantify and compare model capabilities. At their core, these benchmarks are automatic evaluation tools that test for model quality, providing a metric-driven signal to guide developers toward more robust and high-performing architectures.
The modern era of AI benchmarking kicked off in 1998 with the creation of the MNIST dataset. This collection of meticulously labeled 70,000 grayscale images depicting handwritten digits offered a powerful evaluation tool.

This large dataset allowed researchers to train models on one portion of the data and then test performance by running the remaining images through and scoring how accurately the handwritten digits were recognized. With a standardized benchmark, the field now had a common yardstick for comparison. Researchers could iterate on different techniques and architectures, then quantifiably assess which approaches were better.
In 2009, the field took a pivotal leap forward with the launch of ImageNet. The brainchild of Fei-Fei Li, this staggering dataset contained over 14 million images spanning more than 20,000 categories, creating new frontiers for object recognition and computer vision research. ImageNet quickly became the centerpiece of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), an annual contest where the world's AI researchers put their models to the test on image recognition tasks.

For years, traditional computer vision techniques topped the ILSVRC rankings. But in 2012, a powerful new contender emerged from the University of Toronto - AlexNet, a deep convolutional neural network developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton. Hinton's neural architecture won that year, achieving a top-5 error rate of just 15.3% on the ImageNet challenge, 10.8% lower than the next best approach.
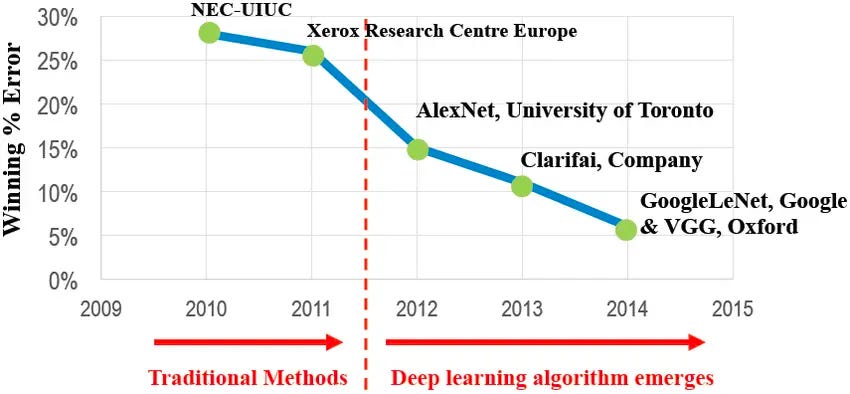
AlexNet's achievement didn't just rewrite the record books; it catalyzed a renaissance in deep learning research. Almost overnight, neural networks shed their also-ran status and became a hotbed of research. Benchmarking was more than just a measuring stick - it was a catalyst for paradigm shifts.
Evolving AI Benchmarks: The Ever-Rising Bar
Benchmarking in AI has been an ever-evolving endeavor, with the community collaboratively raising the bar as models display new groundbreaking capabilities. The creation of datasets like MNIST and ImageNet exemplify this spirit of collective advancement - when researchers develop novel techniques, the field responds by crafting new challenges to quantify and motivate that progress.
Consider the creation of large language models that could code. When OpenAI unveiled Codex in 2021, a derivative of GPT-3 fine-tuned on public GitHub repositories, it represented a new capability. To evaluate this capability, OpenAI introduced the HumanEval benchmark to measure a model's functional correctness in synthesizing programs from text descriptions.
On HumanEval's code writing tasks, stock GPT-3 scored 0%. However, the specialized Codex model, trained on real-world code examples, achieved a remarkable 28.8% - able to generate valid code nearly one-third of the time. HumanEval provided a quantifiable target in the crosshairs, enabling researchers to iterate and enhance code generation performance.
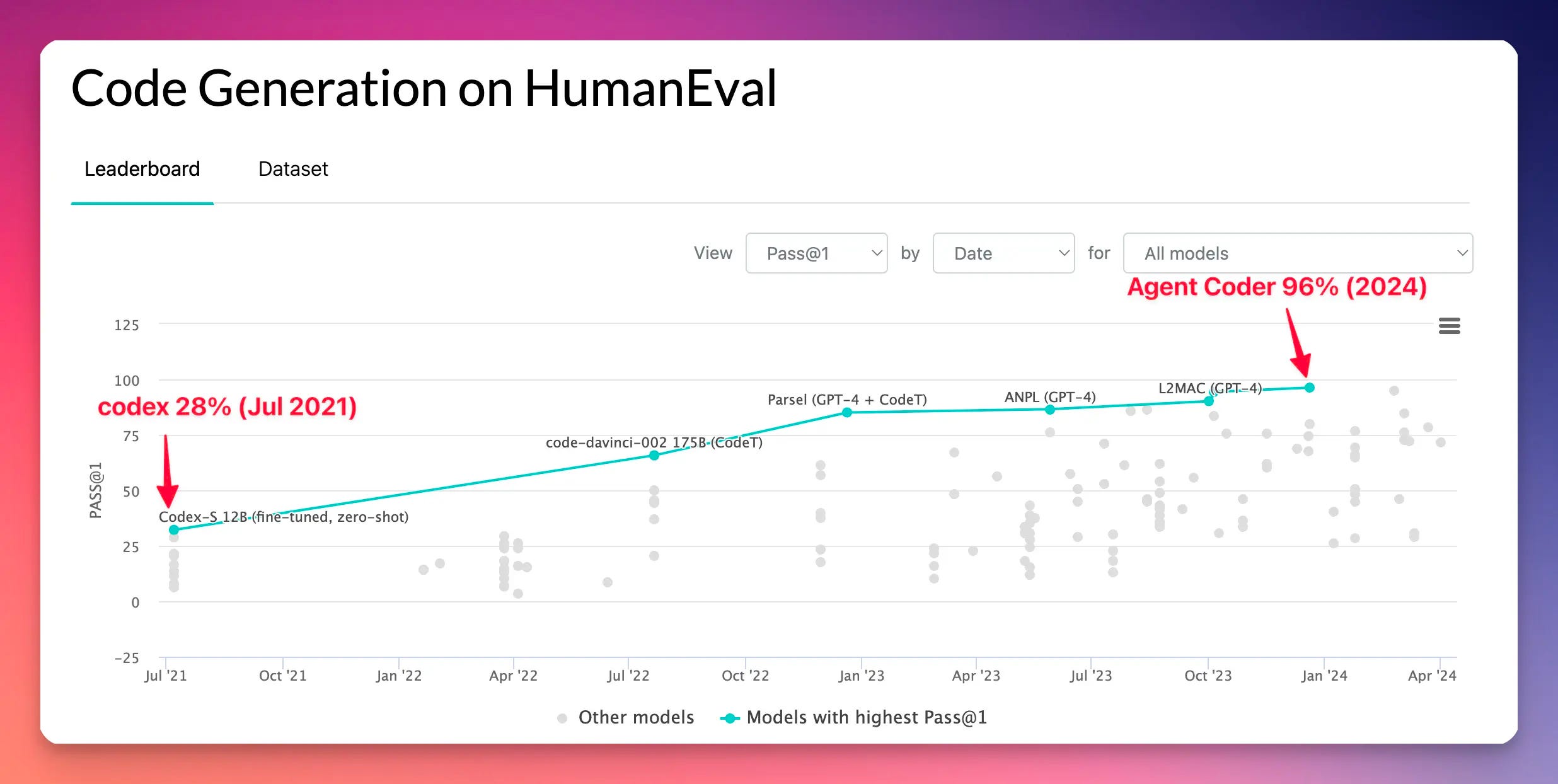
This cycle of benchmarking begetting innovation, which then spurs new benchmarking, has become a driving force in AI's rapid evolution. In 2018, the GLUE benchmark challenged language models across various linguistic understanding tasks. But by 2020, multiple models had surpassed estimated human-level performance on GLUE, triggering the need for a more formidable test.
The research community's response was the Measuring Massive Multitask Language Understanding (MMLU) benchmark. Spanning 16,000 multiple-choice questions across 57 academic disciplines, from mathematics to philosophy, MMLU represented a Herculean general language comprehension challenge. Upon its release, most models performed around random guessing at 25% accuracy, with the powerful GPT-3 mustering just 43.9%.
Example questions from the MMLU
[Astronomy]
What is true for a type-Ia supernova?
A. This type occurs in binary systems.
B. This type occurs in young galaxies.
C. This type produces gamma-ray bursts.
D. This type produces high amounts of X-rays.
[Economics]
When the cross-price elasticity of demand is negative, the goods in question are necessarily
A. normal
B. inferior
C. complements
D. substitutesFor the moment, MMLU has become the standard-bearer for quantifying the cutting edge of language model capabilities. But even as benchmarks like MMLU propel AI progress, the role of benchmarking itself is evolving in concerning ways. It's no longer just a mechanism for testing and improving. Benchmarks are increasingly becoming a key marketing message in the crowded landscape of model builders backed by unprecedented investment dollars.
Benchmark Engineering: Teaching to the Test
Just as the No Child Left Behind era saw teaching practices distorted to "teach to the test," the intense pressure to achieve top benchmark scores is creating similar pressures to engage in benchmark engineering.
For eg: If a model is exposed to material from the MMLU test during training, it's akin to a college student using a leaked final exam to study. However, benchmark engineering can involve other mechanisms, including using different techniques to make apples-to-oranges comparisons.

Google's launch of its Gemini model showcased this benchmarking obfuscation. Gemini's marketing trumpeted achieving a 90% score on MMLU, seemingly outperforming GPT-4's 86.4%. But the fine print revealed that Google used a different prompting approach advantageous to Gemini – an apples-to-oranges comparison. When evaluated under the same 5-shot prompting conditions, GPT-4 actually edged out Gemini, scoring 86.4% to Gemini's 83.7%.

Such benchmark spin and selective framing highlight a broader issue – even when teams avoid outright data contamination, there's ample room to exploit benchmark design quirks and present results in the most flattering light possible. Ultimately, it's the real-world performance, with all its messy logistical complexities, that matters most.
Take Google's highly-touted medical AI for diagnosing diabetic retinopathy, for example. It matched human specialist levels in the lab but stumbled when deployed in Thai clinics. When confronted with the lower-quality images in the chaotic clinical setting, over 20% of patient eye scans were automatically rejected, requiring rescheduled appointments. Nurses found the AI unacceptably rigid compared to their own trained judgment. As Michael Abramoff, a professor at the University of Iowa, remarked, "There is a lot more to healthcare than algorithms."
Beyond Benchmarks: The Rise of "Vibe Checks"
While traditional benchmarks offer a quantifiable measure of large language model (LLM) capabilities, they often fail to capture the nuances of the real-world user experience. Impressive scores on standardized tests don't necessarily translate to an engaging, intuitive interaction. This disconnect has given rise to a new wave of evaluation methods focused on assessing the overall "vibe" of conversing with an LLM.
Leading this charge is the Large Model Systems Organization (LMSYS Org), an open research collaboration founded by students and faculty from UC Berkeley, UCSD, and CMU. In May 2023, they launched Chatbot Arena, a platform that gamifies LLM evaluation through a "hot-or-not" style format. Users are presented with responses from two anonymized LLMs to the same prompt and vote for their preferred answer. Akin to competitive games like chess, each model earns an Elo rating based on these crowd-sourced votes, allowing leaderboard comparisons.
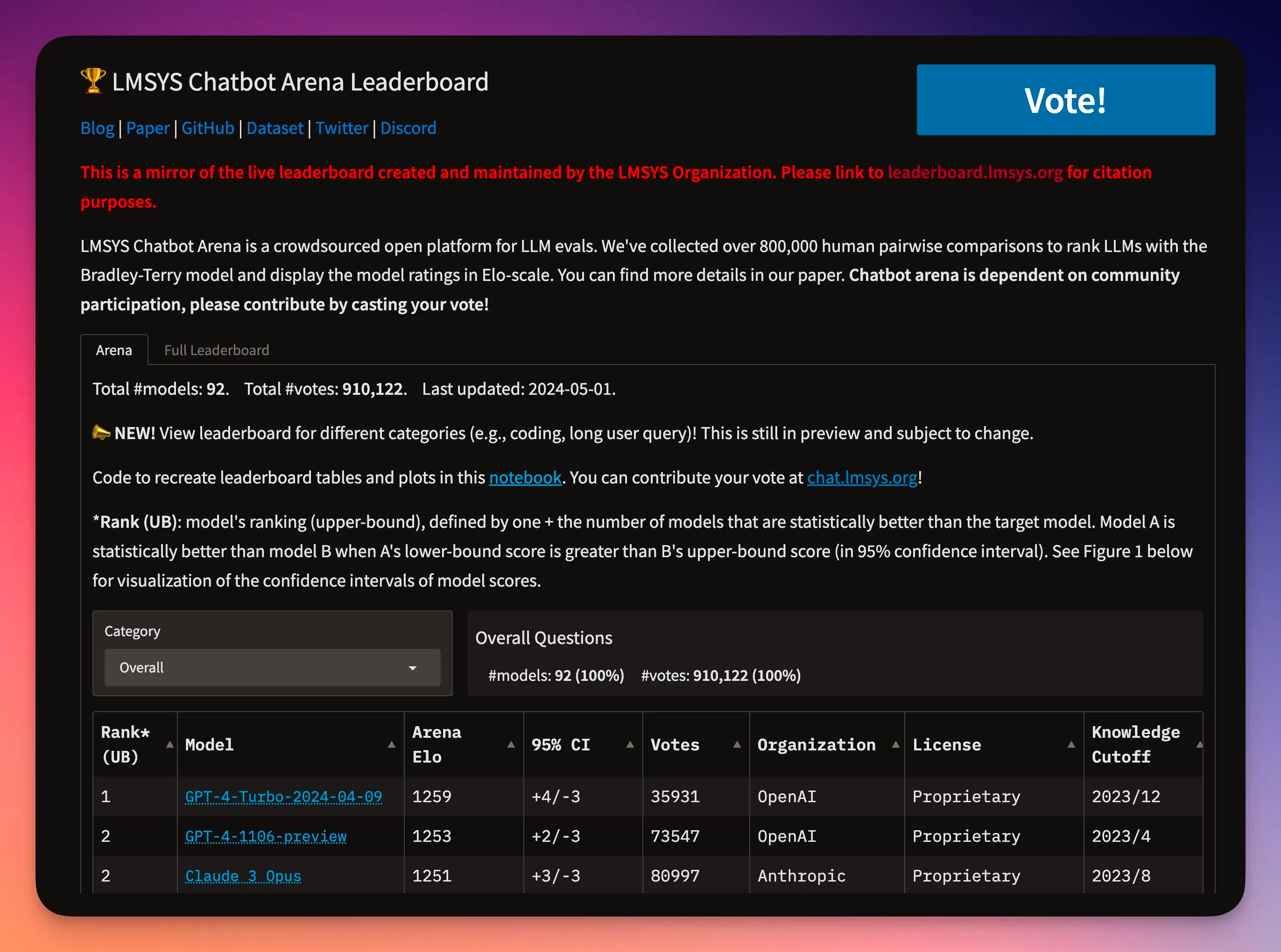
The appeal of this "vibe check" approach is clear - it offers a refreshingly human-centric lens on model assessment. Rather than fixating on narrow benchmarks, it captures something more elusive yet deeply important: how coherent, natural, and engaging does the model feel in practice? With over 800,000 votes across 90+ LLMs tested so far, including giants like GPT-4 and Llama, Chatbot Arena provides a window into collective user sentiment.
But vibe checks are not without flaws. The very popularity-contest nature that makes them insightful also opens the door to potential gaming. Ultimately, both traditional benchmarking and vibe-based evaluation likely have roles to play as the field progresses. Benchmarks offer rigorous baselines, while vibe checks provide an essential gut check on real-world experience. This continuous evolutionary dance - models advancing, evaluations adapting in turn - is part of the larger cat-and-mouse game driving AI development forward.
Perpetual Benchmark Pressure: A Blessing for End-Users
The evolution of AI benchmarking, from academic roots to a high-stakes marketing battleground, has been both impressive and concerning. We've traced its trajectory from foundational datasets like MNIST and ImageNet, to coding tests like HumanEval, to today's MMLU for evaluating large language models. This rapid progress has been catalyzed by AI's transition into a lucrative field awash with investment dollars and marketing frenzies.
Distortion, however, is an inevitable byproduct as the stakes rise higher - benchmark engineering to "teach to the test," misleading framing of results, and the inevitable push for proprietary benchmarks that conveniently favor one's own model. It's the corporate mantra of choosing one's criteria for success writ large, akin to WeWork's infamous "community-adjusted" Ebitda figures.
Yet this phase of metric manipulation is part of any ecosystem's maturation process. Just as the well-intentioned No Child Left Behind education policy ultimately required over 15 years and an overhaul by President Obama's Every Student Succeeds Act to regain flexibility, so too must the AI community be prepared to continually re-evaluate and evolve its benchmarking standards. Initiatives like LMSYS's Chatbot Arena, sharing user data or collaborative efforts on GitHub, provide a countermeasure through transparency.
Ultimately, though, the competitive drive to game and outperform benchmarks is a blessing in disguise for the industry. As long as there is no clear winner, the pressures of one-upmanship will propel developers to iterate, enhance real-world performance, and elevate the entire industry's capabilities. The future of AI will be forged in this crucible of perpetual benchmark battles.