
Off the Mark: The Pitfalls of Metrics Gaming in AI Progress Races
From communist nail factories to capitalist bot battles, this article highlights the eternal risks of bogus benchmarks and blinkered hype cycles derailing meaningful progress.


One of my favorite cautionary tales of misaligned incentives is the urban legend of the Soviet nail factory. As the story goes, during a nail shortage in Lenin's time, Soviet factories were given bonuses for the number of nails produced. Hearing this, the factories reacted by making tiny, useless nails to inflate their output. The regime then pivoted to bonus payouts based on nail tonnage shipped per month — so the factories simply started producing giant, overly heavy nails that were equally useless. This funny yet thought-provoking story has been shared for years as an illustration of how central planning systems can become disconnected from market demand. However, based on my own experience working with tech startups, I have found that this is a common pitfall for any organization. Just as the Soviet bureaucrats ended up befuddled by warehouses filled with pointless tiny nails, the disconnect between benchmarks and real-world value is a challenge we continue to grapple with today.

You Get What You Inspect. Not What You Expect
In the past, I worked for a startup that sold digital advertising space to B2B technology firms' marketing departments. Our platform enabled technology vendors to reach millions of IT professionals at small and medium businesses worldwide. These marketers had quarterly objectives to generate more leads for their sales teams. To achieve their targets, they would design campaigns that directed potential customers to fill out forms and download assets such as whitepapers.
The idea was that these "marketing qualified leads" represented promising potential buyers, screened and primed for sales to pick up. However, in one telling research session, we sat down with the sales team from a Fortune 50 technology vendor. The salespeople told us the marketing leads were nearly worthless for their purposes and that they just ignored them.
The marketing department faced pressure to boost lead generation numbers above all else every quarter. So, they optimized campaigns purely for maximum form fills. It resembled a nail factory from my opening story, focused single-mindedly on one metric measured by central planners rather than actual customer needs.
Metrics Meta-Games: Questionable Wins in the Battle of the LLMs
Reading through the recent announcements and coverage hyping Google's new Gemini language model, I couldn't help but be reminded of the earlier cautionary tales of metrics gone awry. Gemini's product page splashily showcases achieving a 90% score on the MMLU benchmark compared to GPT-4's 86.4%. However, the fine print reveals Google tested Gemini using a different prompting approach not applied to GPT-4's results. Analyzing the actual research paper, GPT-4 edges out Gemini 86.4% to 83.7% using the same 5-shot prompting for a more apples-to-apples comparison.
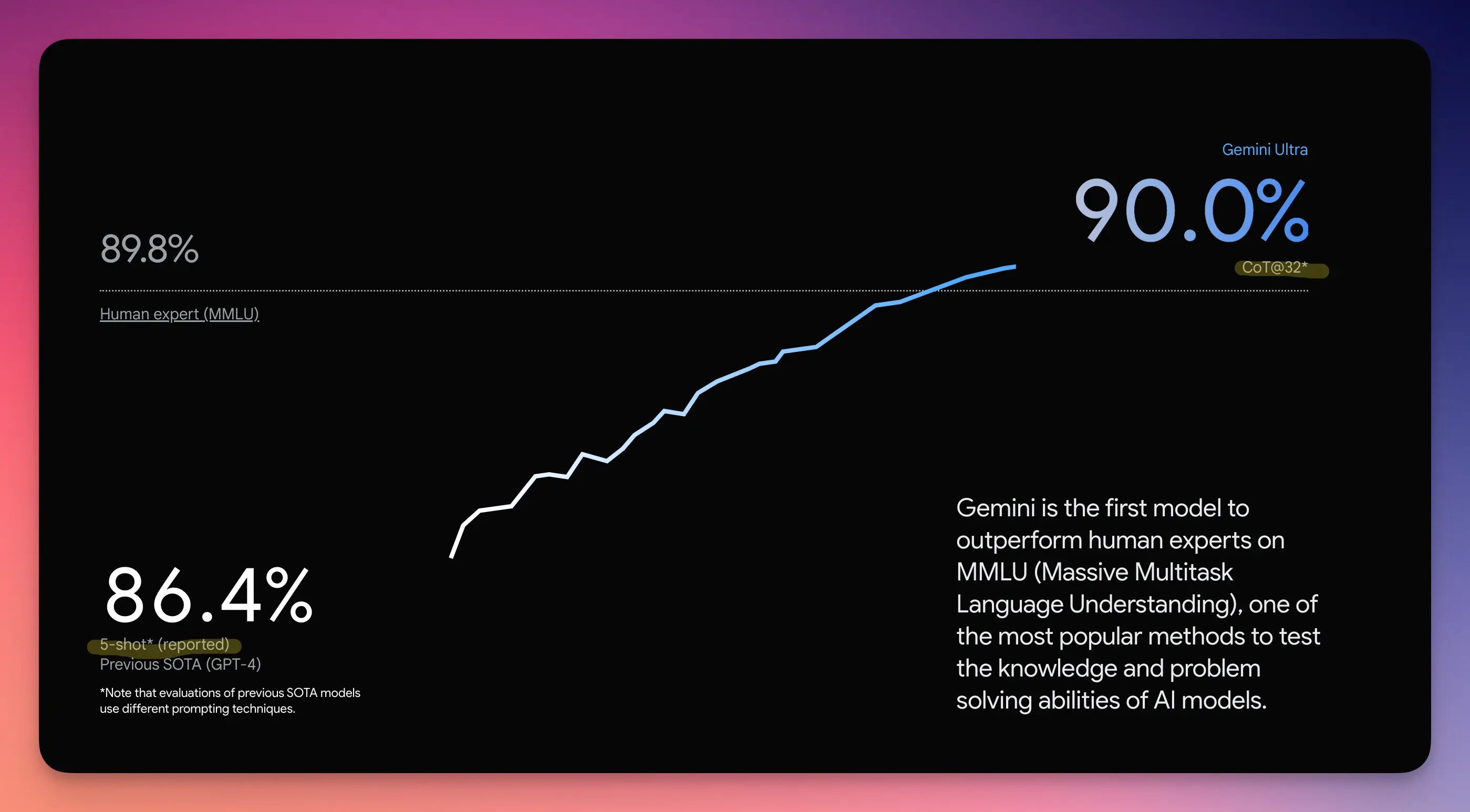
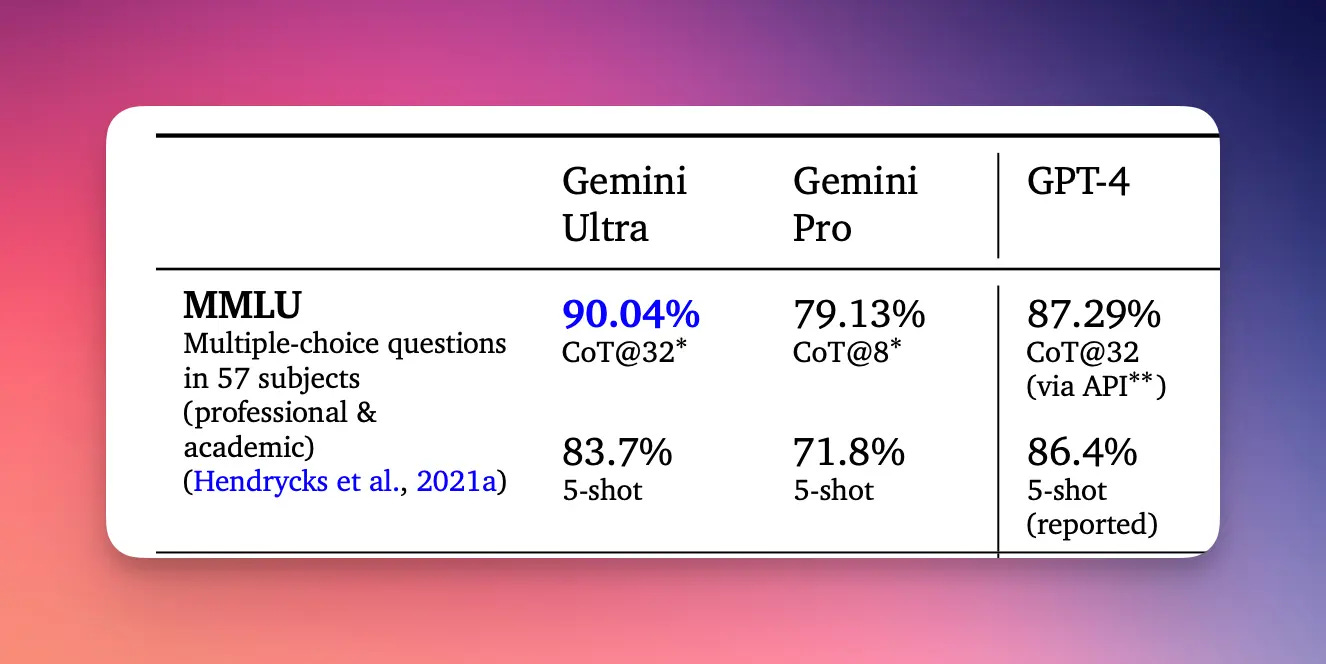
This choose-your-own-adventure style benchmarking allows for announcing whatever claim best suits the story you wish to tell. The flagship Gemini-Ultra model that scored highest isn't even available until next year. Rather than meaningful progress, the bot bout feels more like jousting for tech blog headlines. As metrics become targets themselves, we risk optimization at the expense of progress.
Moving the Goalposts: Benchmark Shell Games
As investments in AI projects rise, so does the pressure to demonstrate substantive "results," often incentivizing benchmark gamesmanship. Consider BloombergGPT - in 2022, Bloomberg leveraged proprietary data troves to train a 50-billion parameter model intended to lead on financial services tasks.
Refreshingly, David Rosenberg, Bloomberg's Head of ML, gave a candid presentation, walking through the technical process. His team was given a stiff deadline of year-end 2022 and a capped budget of 1.3 million GPU hours. They started with an ambitious 710 billion tokens of training data, nearly half from Bloomberg's exclusive corpora. Building on the open-source BLOOM baseline model, the team raced to train a model from scratch. However, training a model is hard - the first two tries failed before the third showed promise. After 42 days of steady training, the model's performance degraded, leaving Rosenberg's team scrambling as budgets and timelines ran dry. Ultimately, they froze what they had, declaring the resulting model "BloombergGPT".
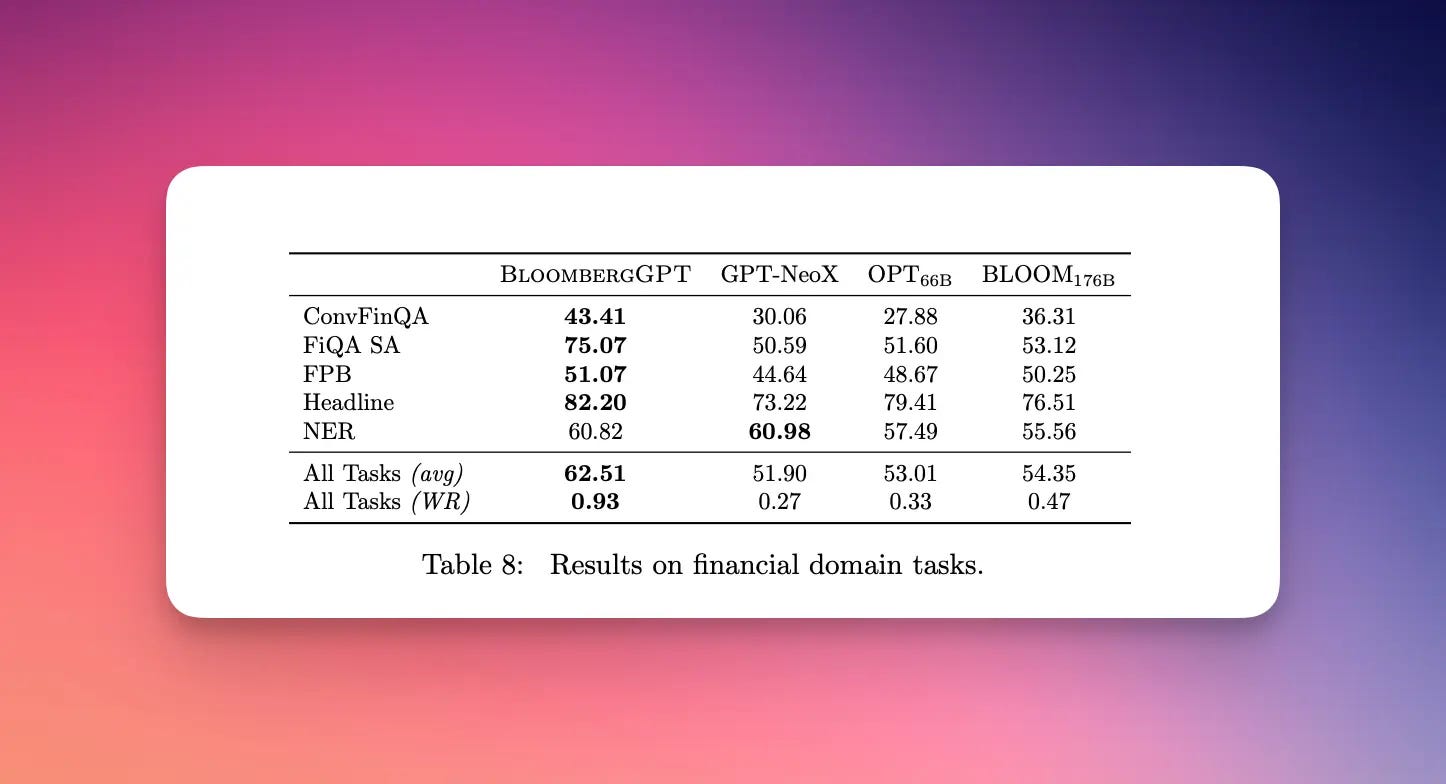
But how did it perform? On general NLP benchmarks, BloombergGPT tested similar to BLOOM. However, the technical paper claimed significant gains in specialized "financial tasks." Yet a closer look reveals these comparisons were only against older open-source models, excluding state-of-the-art GPT-3. A year later, absent continued training, BloombergGPT likely considerably trails leaders like GPT-4 and Gemini.
From the nail-producing Soviet factories to modern AI labs, the pressure to optimize metrics over real-world value persists. It's a reminder of Goodhart's law: When a measure becomes a target, it ceases to be a good measure. Unfortunately, this means we all have to take a closer look to tell what’s actually going on.
