
The Great and Powerful AI: Unveiling the Wizard Behind the Curtain
Exploring the illusion of AI omniscience and the reality of its limitations in multi-turn interactions.


In 1939, moviegoers were transported to the magical land of Oz, where an ordinary girl from Kansas encountered a wizard of seemingly boundless power. The Great and Powerful Oz, with his booming voice and impressive pyrotechnics, awed not just Dorothy and her companions, but generations of viewers. Yet, as the curtain was pulled back, the grand illusion dissolved, revealing nothing more than a clever man with a few tricks up his sleeve.
Fast forward to 2024, and we find ourselves in a new land of Oz—the realm of Generative Artificial Intelligence. Like the wizard of old, modern AI systems present a façade of near-omniscience, effortlessly answering queries on topics ranging from quantum physics to ancient history. ChatGPT and its ilk have become our digital wizards, impressing us with their vast knowledge and apparent understanding. But as we pull back the curtain on these AI marvels, particularly in the realm of multi-turn interactions, we find ourselves face-to-face not with all-knowing entities, but with sophisticated pattern completion systems, each with their own set of smoke and mirrors.
In this article, we'll trace the lineage of today's generative AI models, starting from their modest origins as simple next-token predictors—essentially, glorified autocomplete tools. Like Dorothy's first tentative steps on the yellow brick road, these early models were just the beginning of a journey. As we follow the breadcrumbs of progress, we'll witness the leap from basic text completion to the more sophisticated instruction-following chatbots that now populate our digital landscape. Yet, much like the Scarecrow's quest for a brain or the Tin Man's search for a heart, the attempt to cast these AI models as truly intelligent teammates is proving to be a challenging fit. Despite the glittering promise of the Emerald City of AI, we're discovering that, when it comes to genuine intelligence and understanding, the ruby slippers of capability don't quite fit our digital companions—at least, not yet.
The Humble Beginnings: GPT as a Next Token Predictor
At the core of today's sophisticated chatbots lies a mathematical construct known as a transformer. This architectural backbone of Large Language Models (LLMs) has a primary function that's deceptively simple: to predict the next token in a sequence. This prediction capability, while basic in concept, is the result of training on vast amounts of data.
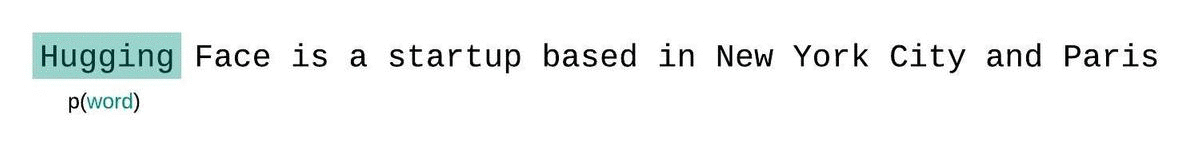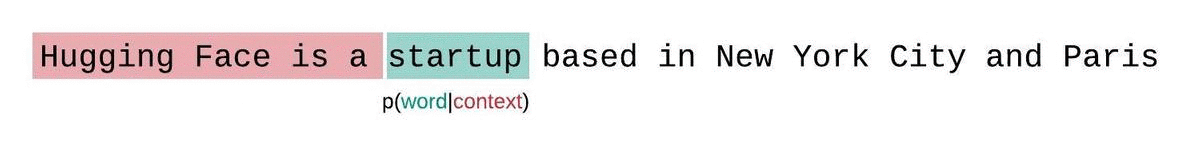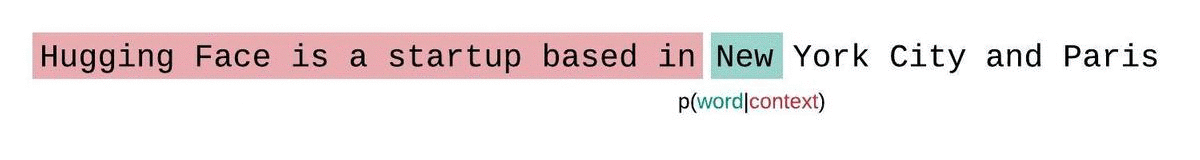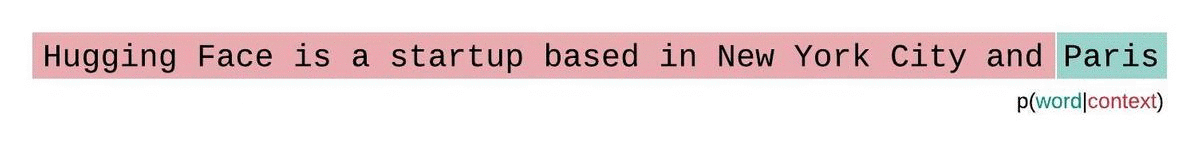
The evolution of GPT (Generative Pre-trained Transformer) models showcases a rapid progression in scale and capability. GPT-1, introduced in 2018, was the initial proof of concept with 117 million parameters. While promising, it struggled with maintaining coherence over longer texts. GPT-2 followed in 2019, significantly expanding to 1.5 billion parameters and demonstrating improved text generation abilities.
The release of GPT-3 in 2020 marked a quantum leap in scale and capability. With a staggering 175 billion parameters, it represented a new era in language models. OpenAI introduced a 'completions' API, allowing users to input a prompt and receive a continuation. This enabled various applications, from article completion to creative writing assistance.
However, early interactions with GPT-3 required careful prompt engineering. The model excelled at continuing text based on initial inputs but lacked the ability to take explicit instructions or maintain context across interactions. For example, if a user input "boxcars.ai has a blog that", the model might complete it with "covers AI strategy and emerging technologies."
As users experimented with these models, they discovered creative ways to simulate conversations. By formatting prompts as dialogue, they could make the model appear to be responding as a chatbot:
roboq6: So why do you want to kill all humans?
GPT Bot: Then the model might complete as
GPT Bot: I'm sorry, but I don't want to kill all humans. As an AI language model, I don't have desires or intentions to harm anyone. My purpose is to assist and provide information to users. I'm programmed to be helpful and ethical, not to cause harm or destruction.This technique gave the illusion of a back-and-forth conversation, even though the underlying mechanism was still just predicting the next most likely sequence of tokens based on the input. The management of the prompt made it look like the AI was "talking" back, when in reality it was simply completing the text in a conversational format.
It's crucial to understand that these interactions were and remain fundamentally "single-turn" and stateless. Each completion was an isolated event, with the model having no memory of previous exchanges. The responsibility for maintaining context and managing the conversation fell entirely on the application calling the API. If an app wanted to reference something from an earlier part of the "conversation," it would need to include that information in each new prompt sent to the model. The GPT model itself wasn't engaging in dialog, but rather responding anew to each carefully crafted prompt. This meant that any semblance of ongoing conversation or context retention was an illusion created by the app's prompt management, not an inherent capability of the model.
If the app needed the model to perform a different task, it couldn't simply instruct it to do so within the same conversation. Instead, it had to construct an entirely new prompt that explicitly guided the model towards the desired output. This limitation meant that while GPT-3 was powerful, it wasn't yet the versatile, instruction-following assistant we see today. It was more akin to an extremely advanced autocomplete tool than a conversational AI. The model could generate impressive continuations of text, but it couldn't easily switch tasks or understand explicit commands within the same interaction.

GPT Learns to Follow Instructions: The Birth of ChatGPT
The evolution from GPT-3 to ChatGPT marks a pivotal moment in the development of AI language models, akin to teaching our digital wizard not just to perform tricks, but to understand and respond to specific requests.
OpenAI's first step in this direction was the creation of InstructGPT. This model was fine-tuned on a dataset of human-written instructions and corresponding completions, teaching the model to follow explicit directions. This was a leap forward, as it allowed users to directly tell the model what they wanted, rather than relying solely on clever prompt engineering.
Building on the success of InstructGPT, OpenAI developed ChatGPT, which took the concept of instruction-following to new heights. ChatGPT was not just trained to follow instructions, but to engage in multi-turn conversations. This was a step-up in human-AI interaction.
A key innovation was OpenAI's integration of the chat technique directly into their API. The new chat completions API allowed applications to send a whole set of back-and-forth conversations to the model. This meant that the model could generate responses based on previous exchanges in the conversation. For example:
input: [
{"role": "system", "content": "You are an AI assistant for boxcars.ai, a company that develops AI-powered logistics solutions."},
{"role": "assistant", "content": "Hello! How can I assist you with boxcars.ai's logistics solutions today?"},
{"role": "user", "content": "What kind of AI does boxcars.ai use for route optimization?"},
{"role": "assistant", "content": "Boxcars.ai uses advanced machine learning algorithms, specifically a combination of reinforcement learning and graph neural networks, for route optimization. This allows us to consider multiple factors like traffic patterns, delivery windows, and vehicle capacity in real-time."},
{"role": "user", "content": "How does this compare to traditional methods?"}]It's important to note that while this approach gave the appearance of the model following along and replying to the user, it was still fundamentally completing the next token based on the entire conversation history provided. The model itself remained stateless – it didn't "remember" the conversation in the traditional sense. Instead, it was responding based on the full context passed to the API with each request.
This advancement allowed for more natural-seeming interactions. For instance, if you had written a paragraph earlier in the conversation and then simply said, "make it shorter," ChatGPT could understand and execute this request without needing the entire context to be restated. This was possible because the model had access to the full conversation history provided in the API call, including the original paragraph. The model's ability to track conversation history and respond appropriately to such context-dependent requests made interactions feel more natural and human-like.
The shift from single-turn interactions to multi-turn conversations opened up new possibilities and sparked imaginations. If an AI could maintain context and follow instructions across multiple exchanges, could we build the long-dreamed-of AI agents? These would be AI systems capable of performing complex tasks, making decisions, and even learning from their interactions over extended periods.
This tantalizing prospect laid the groundwork for the next frontier in AI development: the creation of autonomous AI agents.
The Great Agent Hope
As ChatGPT captured the world's attention, people eagerly sought to connect the bot to the real world. To achieve this, we needed a way for the model to interact with external systems. This functionality, often referred to as "function calling," was initially provided by AI frameworks like Langchain (at boxcars.ai we developed our own for Ruby), and later integrated directly into the APIs by OpenAI and other model vendors.
However, it's important to understand that even with "function calling," we're still working with an auto-complete system. The model itself doesn't actually make function calls or interact directly with external systems. Instead, we've trained the model to respond with specific codes or formats when it determines that an external action is needed. For example:
Human: What's the weather like in New York today?
AI: To answer this question, I need to check the current weather data for New York. I'll use the getWeather function to retrieve this information.
[FUNCTION CALL]
{
"name": "getWeather",
"parameters": {
"location": "New York",
"date": "today"
}
}
[/FUNCTION CALL]The model doesn't execute this function call itself. Instead, the system surrounding the model (often referred to as the "orchestrator" or "agent framework") interprets this output. The orchestrator then makes the actual API call to a weather service, retrieves the weather information, and feeds it back into the model as part of the conversation history. The model can then use this information to generate a human-readable response about the weather.
This clever integration of function calling, combined with the model's ability to engage in multi-turn conversations, created a powerful illusion of intelligence and capability.
With models now capable of engaging in multi-turn conversations and seemingly interacting with the real world through APIs, it appeared we had pulled back the curtain on a new Emerald City of AI. The clever smoke-and-mirrors of the API, combined with the model's confident responses, gave the impression that independent AI-driven agents were just around the corner.
However, as we've ventured further down this yellow brick road, we've discovered that the path is more complex. Remember that we're still building on what is essentially an advanced auto-complete system. The model doesn't have a state machine or any control structure. The "instructions" we give it are just part of the auto-complete prompt. This can lead to complications when trying to build an agent in the real world that needs to keep track of its work and adhere to specific constraints.
Sean Wu's blog post, "Can ChatGPT be prompted to take food orders? It is complicated", provides an excellent illustration of these challenges. Wu explores the construction of a food ordering chatbot using the following prompt:
You are OrderBot, an automated service to collect orders for a pizza restaurant.
You first greet the customer, then collects the order,
and then asks if it's a pickup or delivery.
You wait to collect the entire order, then summarize it and check for a final
time if the customer wants to add anything else.
Finally you collect the payment.
If it's a delivery, you ask for an address.
Make sure to clarify all options, extras and sizes to uniquely
identify the item from the menu.
You respond in a short, very conversational friendly style.
The menu includes
pepperoni pizza 12.95, 10.00, 7.00
cheese pizza 10.95, 9.25, 6.50
eggplant pizza 11.95, 9.75, 6.75
fries 4.50, 3.50
greek salad 7.25
Toppings:
extra cheese 2.00,
mushrooms 1.50
sausage 3.00
canadian bacon 3.50
AI sauce 1.50
peppers 1.00
Drinks:
coke 1.00, 2.00, 3.00
sprite 3.00, 4.00, 5.00
bottled water 5.00 However, conversations can go awry:
Bot: Hello! Welcome to our pizza restaurant. How can I assist you today?
User: one cheese pizza and three drinks
Bot: Great! Just to confirm, would you like a small, medium, or large cheese pizza? And which drinks would you like and in what sizes?
User: large
Bot: Got it! So that's one large cheese pizza and three drinks. Which drinks would you like and in what sizes? We have Coke in small ($1.00), medium ($2.00), and large ($3.00), Sprite in small ($3.00), medium ($4.00), and large ($5.00), and bottled water for $5.00.
User: coke
Bot: Sure thing! And what size would you like the Coke to be? Small, medium, or large?
User: small
Bot: Great! So that's one large cheese pizza and one small Coke. Is there anything else you'd like to order or is that all for now?In this example, the bot asks for follow-up on the type of drink but "forgets" the number of drinks initially requested. Understanding that this is just auto-complete at work helps explain what's happening. In each interaction, the conversation thread contains all these back-and-forths and possibly even revisions. There's no state machine with a control structure keeping track of the order in a database. It's just statistically auto-completing based on the prompt.
This means that as the prompt gets longer with potentially conflicting information, the model can behave erratically. If a user were to say "actually make that 4 drinks" later in the conversation, the model might struggle to consistently maintain this updated information throughout the interaction.
These challenges highlight the gap between the illusion of intelligent agents and the reality of working with language models. While we've made significant strides in creating more interactive and context-aware AI systems, we're still far from achieving truly autonomous AI agents capable of reliably managing complex, real-world tasks.
Can We Train Models to Overcome These Challenges?
We've come a long way from Kansas, or in this case, from simple auto-complete. Who knew that the technology behind predicting the next word in a sentence could evolve into systems capable of making API calls and performing such seemingly magical feats as we're witnessing with today's LLMs?
Each step in this journey has required the creation of new, specialized datasets. To build InstructGPT, OpenAI had to curate a dataset of human-written instructions paired with appropriate responses. This allowed the model to understand and follow explicit directions. Similarly, to enable function calling, datasets were created that taught models to recognize when external actions were needed and how to format those requests.
But can we apply the same approach to multi-turn interactions that require engagement with the real world?
In anticipation of where the field is heading, researchers at UC Berkeley unveiled a new benchmark in September 2024: The Berkeley Function-Calling Leaderboard (BFCL) V3. This benchmark is designed to validate how models perform on complex, real-world tasks. The latest version includes support for multi-turn and multi-step function calling, pushing the boundaries of what we expect from our AI assistants.

BFCL V3 introduces several key challenges:
Multi-Turn and Multi-Step Function Calling: It assesses how models handle complex scenarios requiring multiple interactions and function calls within a single interaction.
Missing Parameters: The dataset includes scenarios where required information is missing, testing the model's ability to identify and request follow-up information.
Missing Functions: Some scenarios intentionally withhold certain functions, challenging the model to recognize when it lacks necessary tools and request them.
Long-Context Multi-Turn: This tests the model's ability to handle large amounts of information, simulating real-world API outputs that can be overwhelming.
Composite Scenarios: These combine multiple challenges to create extremely difficult scenarios that test the model's ability to function as an autonomous agent in complex situations.

So, how do the top models perform on this multi-turn assessment? The current leader, GPT-4o (OpenAI's new reasoning model), gets it right about 25% of the time. In other words, it's typically more wrong than not. These results highlight the significant challenges that remain in creating truly reliable AI agents.
However, we shouldn't lose hope. Just a few quarters ago, the summit of our current peak was but a vision. We hoped for a model that could make API calls, and today that's baked into our assumptions. Now, we need a model that can understand when it's missing data or a tool and ask for it. Until we can train models to do that, any agent applications are bound to go off the rails.
As we pull back the curtain on our AI wizard, we find not an all-knowing entity, but a system still learning to navigate the complexities of multi-turn interactions and real-world engagement. Like Dorothy and her companions, we've discovered that the magic we sought was within us all along—in our ability to innovate, to create new datasets, and to push the boundaries of what's possible.
The yellow brick road of AI development stretches on, with new challenges and opportunities on the horizon.