
The Digital Manhattan: What's Your Data Really Worth in the AI Age?
How online platforms like Reddit are navigating the strange new waters of AI data licensing.


In 1626, a small Dutch boat pulled up to the shores of what we now know as the island of Manhattan. Peter Minuit, the director of the Dutch West India Company, stepped onto the land with a proposition that would become the stuff of legend. As famously depicted in the 1907 painting by Alfred Fredericks, Minuit met with the local Lenape tribe and struck a deal: the entire island of Manhattan for 60 guilders worth of trade goods—roughly equivalent to $24 in modern currency. But here's the rub: the concept of land ownership was foreign to the Lenape. They didn't share the European notion of property rights. How could anyone "sell" something that, in their worldview, couldn't be owned?

As I ponder this historical misalignment of values and concepts, I can't help but see echoes in our digital age. Imagine a corporate development executive from a tech giant, not unlike our Dutch traders of yore, reaching out to an online platform with an offer: "We'd like to purchase the rights to your content to train our latest AI model." The platform? Reddit. The buyer? OpenAI. Just as the Lenape grappled with assigning value to something they'd never considered as property, we now face the challenge of pricing our digital footprints, our collective knowledge, our very thoughts translated into bits and bytes. This article will explore this modern conundrum: How do we assign value to something we've never had to price before? In this new frontier of AI and data, are platforms and publishers unwittingly trading away digital Manhattans for handfuls of virtual beads?
The Data Dilemma: From Web Crawls to Walled Gardens
The early days of language model training were akin to a digital gold rush. AI researchers and companies, armed with powerful web crawlers, set out to mine the vast expanse of the internet for data. Tools like Common Crawl became the pickaxes of this new frontier, scooping up enormous amounts of text from across the web, including copyrighted material and personal information. The prevailing attitude was simple: if it's public, it's fair game.

But as AI models grew more sophisticated and their potential impact became clearer, the landscape began to shift. A recent study by the Data Provenance Initiative, an MIT-led research group, has shed light on a dramatic change in this digital ecosystem. The study, aptly titled "Consent in Crisis," examined 14,000 web domains included in three commonly used AI training datasets: C4, RefinedWeb, and Dolma.
The findings are striking. An estimated 5% of all data across these datasets, and 25% of data from the highest-quality sources, has now been placed off-limits to AI crawlers. Website owners are increasingly using the Robots Exclusion Protocol, a method as old as the web itself, to prevent automated bots from accessing their content. This protocol, implemented through a simple file called robots.txt, acts as a "No Trespassing" sign for AI data gatherers.
But the restrictions don't stop there. The study revealed that up to 45% of the data in the C4 dataset is now protected by websites' terms of service. This means that even if the data is technically accessible, using it for AI training could violate legal agreements.
From Web Crawls to Corporate Deals: The New Data Landscape
This shift in data availability is driving a new phase in AI development, one where negotiation, licensing, and partnerships are becoming crucial. As model builders look for a data edge, they're now approaching publishers and platforms directly, seeking to license data for use in model training. This new approach is exemplified by the deal between Reddit and OpenAI.
In their S-1 filing, Reddit revealed a data licensing arrangement. The filing states, "In January 2024, we entered into certain data licensing arrangements with an aggregate contract value of $203.0 million and terms ranging from two to three years. We expect a minimum of $66.4 million of revenue to be recognized during the year ending December 31, 2024 and the remaining thereafter." This deal represents a new and substantial revenue stream for Reddit which made about $800M in 2023.
To understand the significance of this deal, we need to first grasp how platforms like Reddit function and why their data is so valuable. At their core, these platforms are built on user-generated content and community engagement. Here's how the cycle typically works:
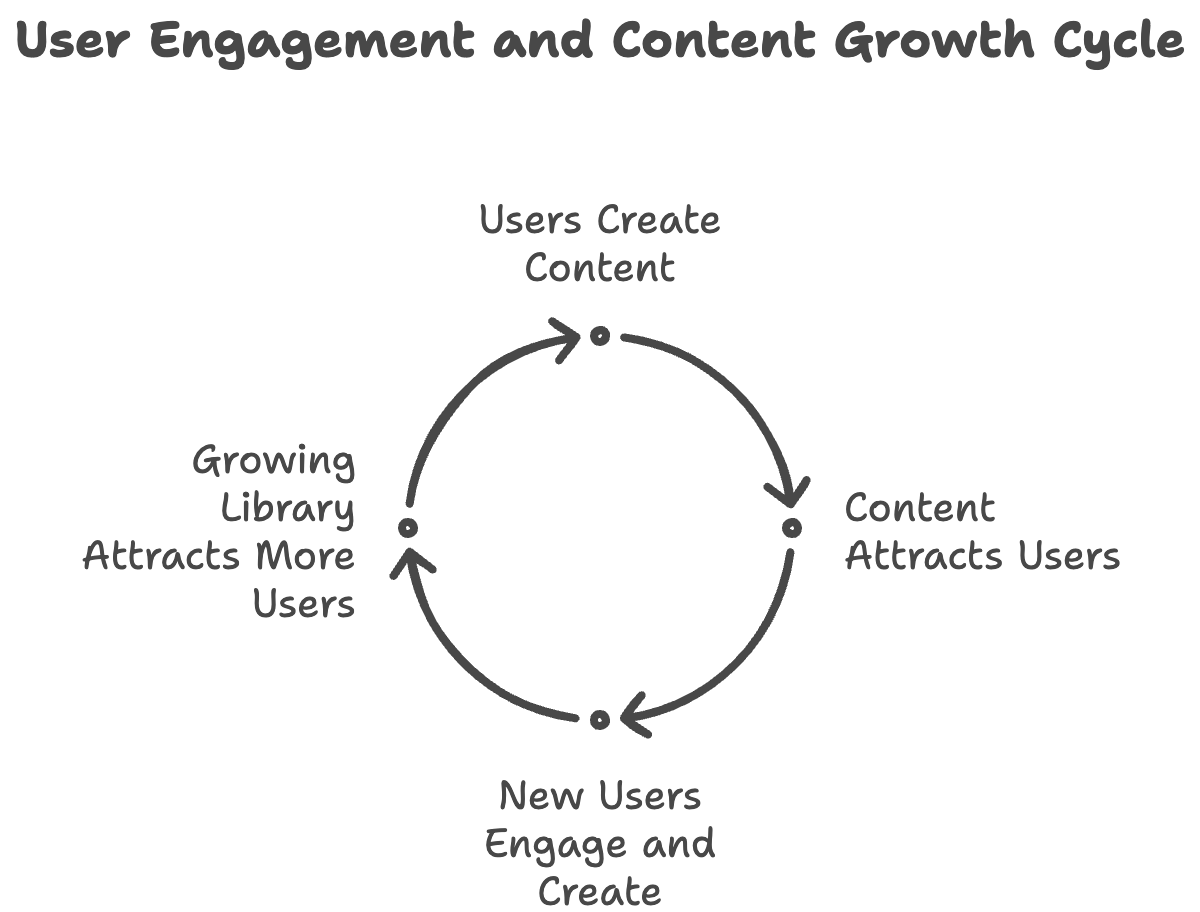
Users create content (posts, comments, questions)
This content attracts other users through search engines or social sharing
New users engage with existing content and create their own
The growing content library attracts even more users
The cycle continues, creating a rich, diverse, and ever-expanding knowledge base
This self-reinforcing cycle is what makes platforms like Reddit so valuable. In 2023 alone, Reddit saw an estimated 469 million posts published, an 11.14% increase from the previous year. That's an average of 1.2 million posts per day, or a staggering 438 million posts per year. Each of these posts potentially attracts new users, who in turn contribute more content.
I've seen this dynamic firsthand. During my time running a community of 6 million IT professionals—think StackOverflow, but for IT—our growth was driven by our extensive back catalog of content. IT professionals would find our site through search engines, engage with existing content, and then stay to ask their own questions or contribute their expertise.
However, licensing this data to an AI company presents a unique challenge. Unlike traditional licensing deals, providing this wealth of data to a Large Language Model (LLM) is a fundamentally different proposition. These AI models don't just reference the data; they learn from it, integrate it, and can potentially reproduce similar content.
The Bargain: Short-Term Gain vs. Long-Term Survival
In the world of online communities and content platforms, licensing data for AI model training is a new thing. It's a tempting proposition - substantial revenue in exchange for data that's already publicly available. But the long-term implications could be existential.
Unlike traditional licensing deals, where content is simply displayed elsewhere with clear attribution, AI training data becomes integrated into the very fabric of the model. The model doesn't just reference this data; it learns from it, synthesizes it, and can generate new content based on it. This means that an AI model trained on Reddit's data could potentially answer questions and generate discussions that closely mimic those found on Reddit itself.
This poses a threat to the virtuous cycle that drives online communities. If users can get Reddit-like responses from an AI model, then it's likely they don't visit Reddit, post questions, or engage in discussions. The platform risks cutting off the source of its value - user engagement and content creation.
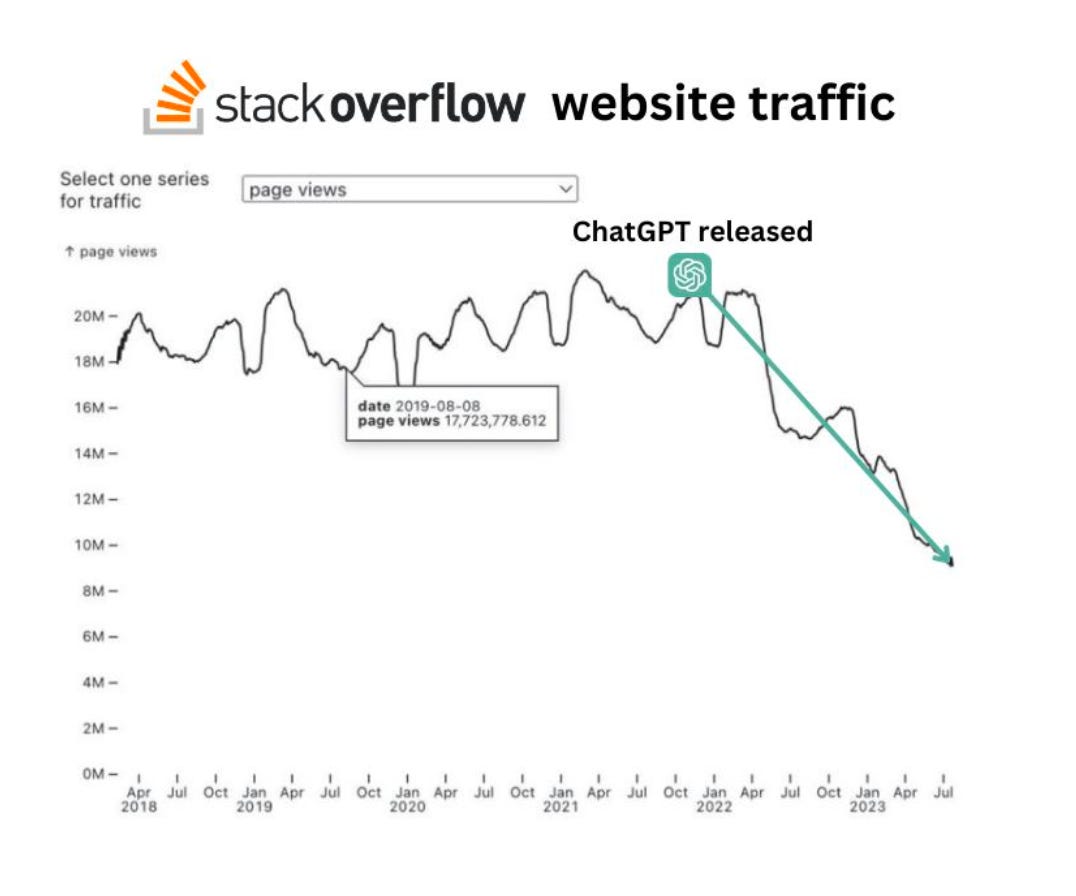
We've already seen early signs of this impact. Stack Overflow, a cornerstone of the programming community, saw a significant traffic decline following the release of ChatGPT.
Yet, platforms like Reddit find themselves in a challenging position. If they don't license their data, there's no guarantee that AI companies won't build comparable datasets from other sources. The choice seems to be between potentially hastening their own obsolescence or missing out on substantial revenue while possibly facing the same fate.
This dilemma brings us full circle to our opening analogy of the Lenape and Manhattan. If the Lenape had a premonition of how the sale of Manhattan would fundamentally alter their way of life, would they have made a different choice? It's a tantalizing thought experiment. Investor Mohnish Pabrai once noted that if the Lenape had access to an investment office achieving a 7% annual return from 1626 to today, their $24 would now be worth over $7 trillion.
It'll be interesting to see how the growth and monetization of community sites like Reddit will evolve in the coming years.