
Decoding the Linguistic Matrix: From Ones and Zeros to Contextual Meaning
Exploring AI's leap from processing language symbols to comprehending the rich tapestries of meaning woven within.


Neo's perception of reality is shattered in the climactic hallway scene from the iconic 1999 sci-fi film The Matrix. The walls and ceilings of the hallway ripple and distort into cascading streams of green code—cryptic hieroglyphs of ones and zeros flowing like neon-tinted digital rivulets. In this breathtaking moment, the protagonist transcends his limitations to glimpse the true nature of the Matrix's cyberpunk dystopia. He sees the relationships and connections that hold it together and can move through it like never before.
For the bulk of their history, computers have mirrored Neo's journey in reverse. Since the 1940s, computers have exclusively trafficked in low-level machine code, precisely juggling voltage states represented by ones and zeros. While incredibly adept at manipulating these binary building blocks, the machinery remained blind to the meaning of the numbers.
Only in recent decades have we begun chipping away at this blindness. This article will trace the origins of these efforts, from the early schemes to translate human language into computer code like ASCII to modern breakthroughs like word embedding models.
From Symbols to Semantics
Computers operate on binary data - ones and zeros - while humans communicate through language. This means we had to find a way to translate our words into numbers that machines could manipulate. Fortunately, we had experience with this problem - telegraphy also required mapping text onto standardized electrical pulse codes like Morse, with its iconic dots and dashes.
For digital computers, the ASCII standard emerged in the 1960s to map the English alphabet and basic punctuation to 128 unique binary values. While ASCII unlocked advances like digital text storage, data transmission protocols, and word processing applications it was still very limited.
This spurred the development of Unicode in the late 1980s - a universal encoding capable of representing over 143,000 characters across 154 modern and historical scripts. Today, thanks to Unicode standards, when I type an emoji for 🚆 it displays across many screens from different vendors without a problem.
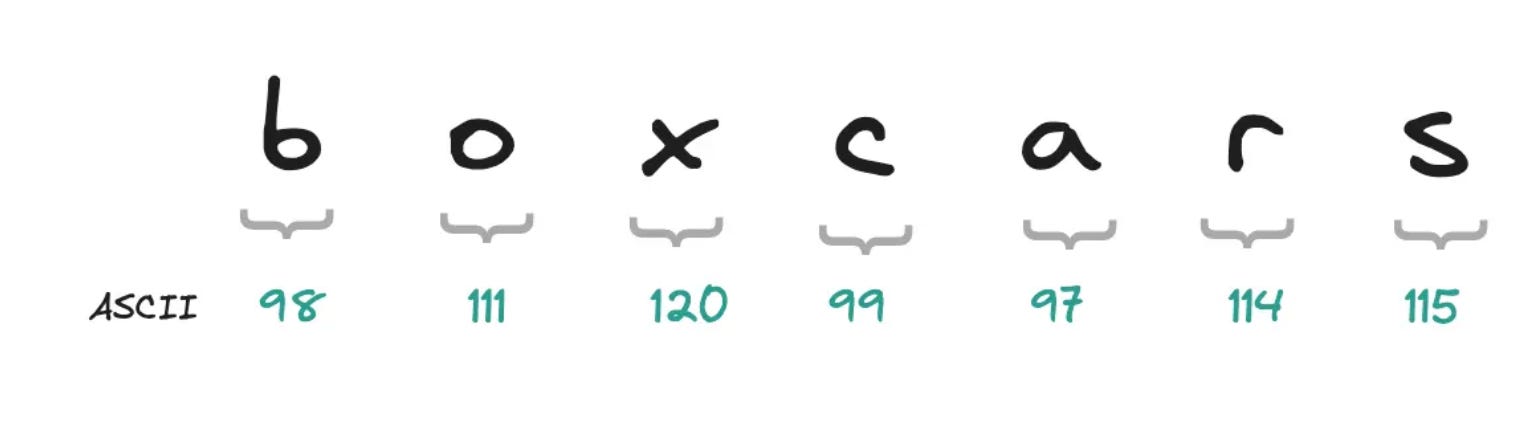
The ability to reliably convert words into numerical codes allowed our computer revolution to take flight. Yet this symbolic mapping between glyphs and binary values was fundamentally devoid of meaning. To an early computer parsing ASCII, the word "boxcars" was just an arbitrary sequence of numbers (98, 111, 120, 99, 97, 114, 115) with no inherent relationship to the real-world concept of freight train cars used to transport goods.
To illustrate the limitations, imagine using an early text search engine to organize files about your model train hobby. You create documents like "boxcars.txt" describing different rail car varieties and "goods_train_evolution.txt" chronicling the historical importance of freight transportation. When searching for information on "boxcars," the naive search system can only match the explicit character pattern (boxcutter, boxes, boxcar), failing to recognize the conceptual link between "boxcars" and the synonymous "goods trains."
This kind of scenario played out constantly as we slowly digitized the world's knowledge into databases, documents, and websites. Our technology could store and retrieve symbolic representations, but it lacked the capacity to intuit meaning or semantic relationships between them. This meant that rule-based software systems to calculate profit & loss statements could be built, but answering a user's query for a recipe for "something warm to enjoy on a cold winter evening" would blow the circuits.
And the need to answer these queries was pressing. Take Google's multi-billion dollar advertising business as an example. Billions of queries were being matched purely on keywords, missing the opportunity to serve users the links (and ads) they wanted.
Decoding Meaning
A word is characterized by the company it keeps
J.R. Firth, English Linguist in the 1950s
Researchers' path toward helping machines grasp relationships and meaning traces back to a unifying hypothesis in the field of natural language processing. Known as the "distributional hypothesis," this idea proposed that words appearing in similar linguistic contexts tend to hold similar meanings. i.e. —the company a word keeps signals the concept it embodies.
The statistical patterns of how words naturally clustered and co-occurred across massive text corpora contained valuable clues about their underlying semantics. Analyzing the contexts in which "boxcar" and "goods train" appeared across millions of books, websites, and data sources, algorithms could potentially deduce their semantic kinship.
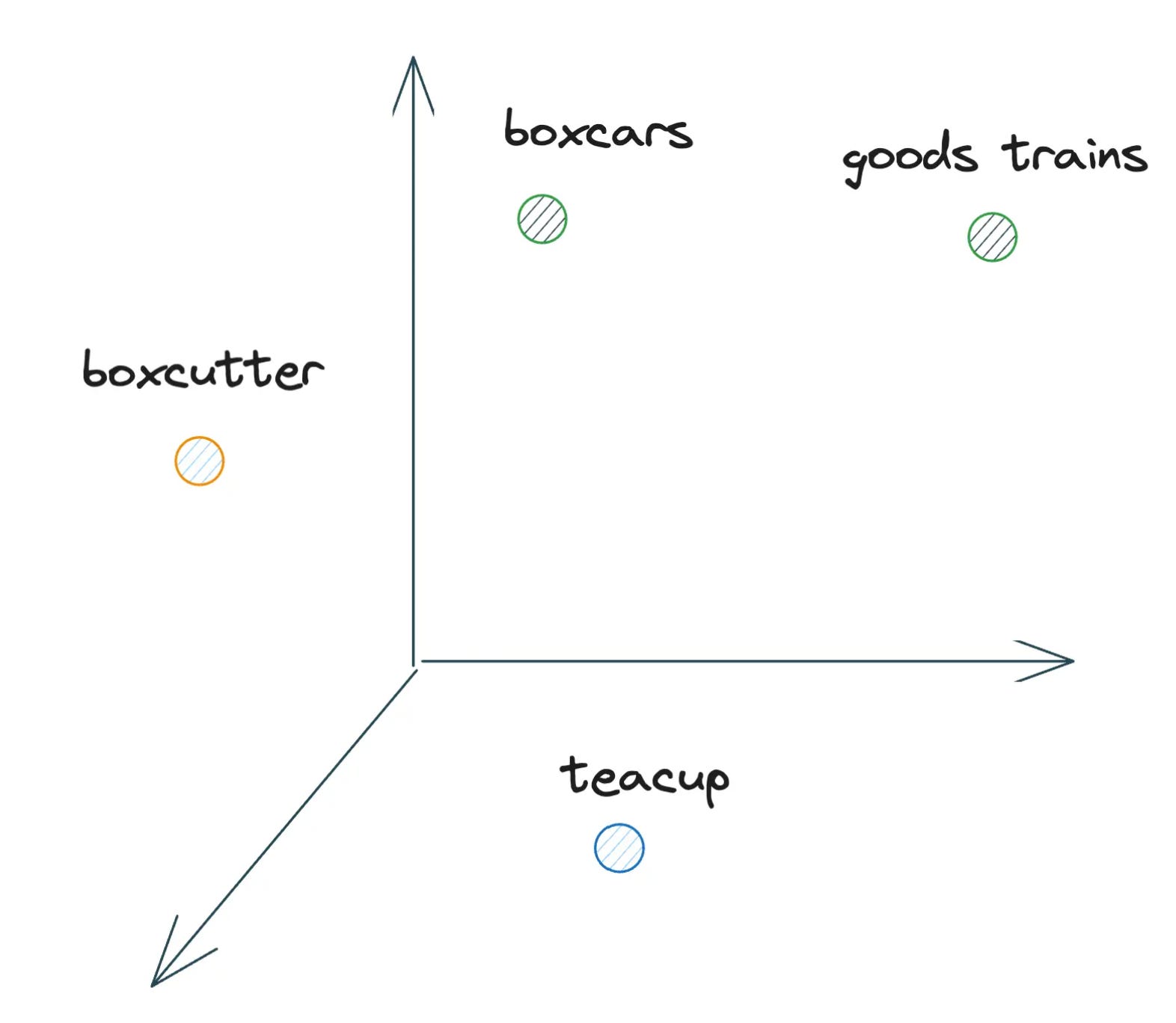
For instance, across those sprawling corpora, the word "boxcar" would frequently appear in close proximity to phrases like "goods train", "freight car", "railcar", and other cargo transportation terminology. In contrast, the contexts surrounding the word "teacup" would skew heavily toward kitchenware, drinkware, and tabletop vocabulary. By detecting and encoding these contrasting distributional patterns, language models could surface the insight that "boxcar" is more like "goodstrain" than "boxcutter" or "teacup".
This insight sparked efforts to develop new machine-learning techniques for extracting word meanings from their natural distribution properties in text. The breakthrough arrived in 2013 with word2vec, a neural network model from Google. At its core, word2vec leveraged the distributional hypothesis to efficiently learn the relationships and encode them as a vector.
Why vectors? Unlike encoding schemes like ASCII and Unicode, which map each character to a single value, these vector embeddings represent words as points in a multidimensional space. In the illustration above, we can visualize "teacup" as a point on the floor of a 3D space, while "boxcar" occupies a distinct position on one of the walls. Vectors provide a powerful mathematical framework for representing these embeddings across many dimensions, allowing semantically similar words to be mapped to neighboring points clustered together.

But these embeddings unlocked more than visualizable semantic relationships. Simple vector arithmetic could now turn surface-level word analogies into semantic operations over the embedded conceptual space. For example:king - man + woman = queen.
While still an oversimplification of the true complexities of language, embedding models were a first step towards understanding.
The Contextual Frontier
While vector embedding models like word2vec began capturing semantic relationships between individual words, a new frontier remained - grasping the full meaning of those words within rich multi-word contexts like sentences. Consider the word "bat" - its meaning shifts depending on the context:
"The bat flew out of the cave."
"The player swung the bat."
To understand whether "bat" refers to the winged mammal or a piece of sports equipment, language models needed to "pay attention" to the surrounding contextual words like "flew" versus "swung." Static word embeddings alone could not resolve these situational semantics.
This challenge was finally cracked by the emergence of the Transformer architectures in 2017. Built around a powerful self-attention mechanism, these models could associate words with their relevant contexts, producing contextualized representations aware of the full linguistic scenery around each token.

This contextual awareness proved pivotal for a range of language tasks like machine translation. The screenshot above illustrates how the meaning of "it" changed based on the gendered nouns it referred to when translating between languages. By paying attention to the context, the Transformer could accurately render the pronoun based on the semantics of the surrounding words.
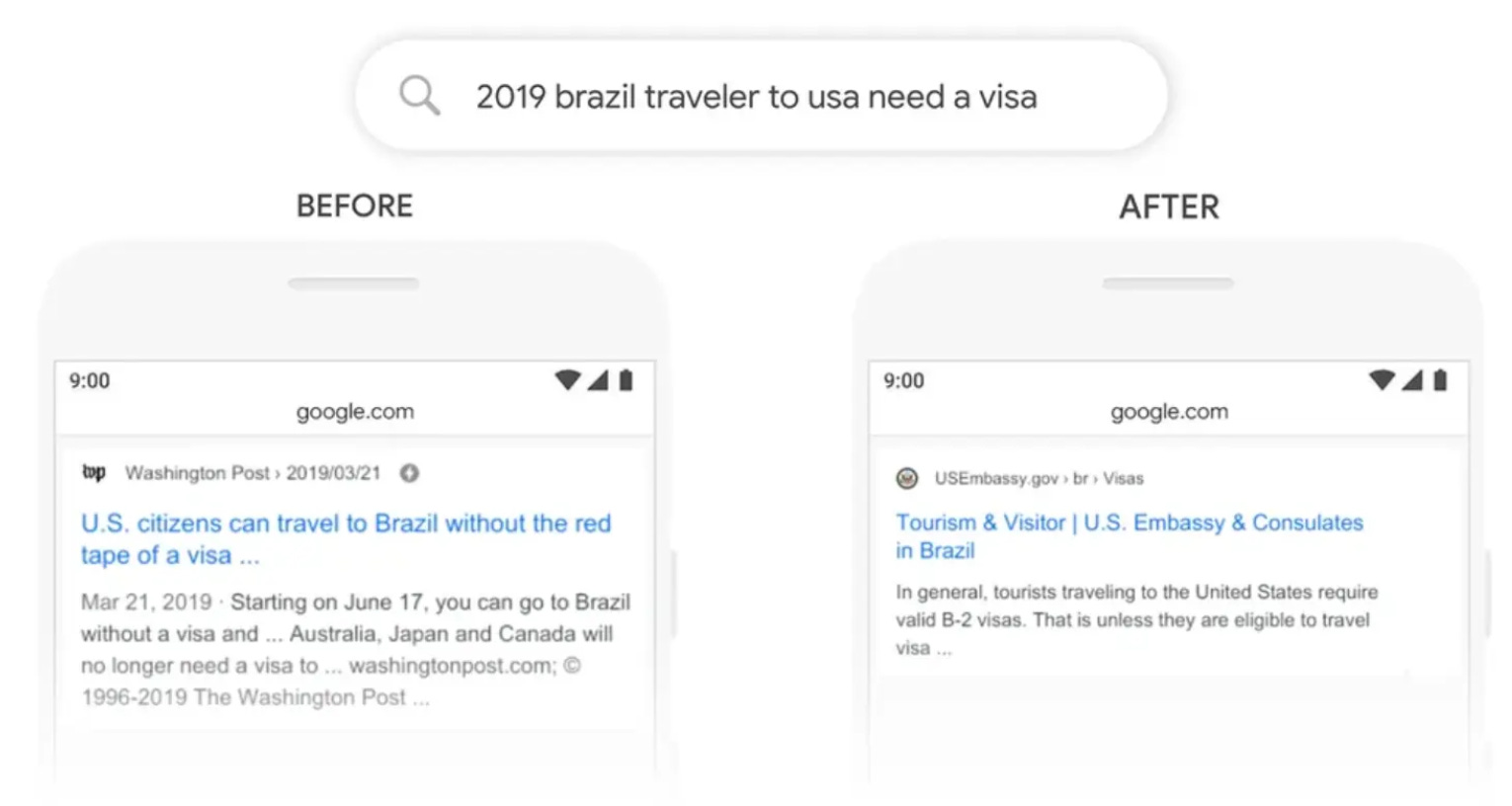
This contextual language representation breakthrough paved the way for the BERT model released by Google in 2018. The example above showcases BERT's impact on Google Search. Before this contextual model, the query "brazil traveler to usa need a visa" prioritized irrelevant results about U.S. visitors to Brazil based on basic keyword matching. However, by understanding the context and importance of words like "to," BERT surfaced the most relevant pages actually addressing Brazilian travelers to the United States needing a visa.
Just as Neo's awakening allowed him to bend and manipulate the Matrix's coded reality, the rise of language models has enabled machines to finally perceive and navigate the meaning woven into human communications. What began as schemes to encode our symbols into 1s and 0s advanced to word embeddings capturing semantic relationships. But with the Transformer architectures, we have crossed the threshold into computers starting to understand.
It's still early days, and like Neo's journey in the Matrix, there is still much to learn. But we're beginning a journey where computers can understand our world and participate in it.