
Copyright, AI, and the Murky Present: From Mickey Mouse to Machine Minds
Tracing the journey of copyright law, from the rise of Mickey Mouse to the emergence of LLMs.

Back in 1928, the world first met Mickey Mouse in 'Steamboat Willie,' a short film that did more than introduce a cheeky character—it spotlighted the complex dance between creativity and copyright. That animated character, with his infectious grin, became an unexpected emblem of a century-long debate. Far from just being an icon of cartoon whimsy, Mickey's journey through the annals of copyright law paints a vibrant prelude to today's digital age tussles, where AI adds even more layers to the intricate tapestry of intellectual property.

Copyright Chronicles: From Quills to Cartoons
In 1790, the U.S. inaugurated its copyright framework, offering creators a 14-year protective term, renewable for another 14 years. Originally crafted for books, maps, and charts, the scope soon expanded to include forms like music and paintings. Fast forward to the 20th century, and Walt Disney Studio faced a looming reality: 'Steamboat Willie' was on the verge of becoming public domain by 1984. Disney rallied for lengthier protections to forestall this, leading to the Copyright Act of 1976. Their advocacy didn't end there. The 1998 Copyright Term Extension Act, wryly termed the "Mickey Mouse Protection Act" by naysayers, stretched these protections even further.
But as copyright's territory expanded, voices of dissent grew louder. Eric Eldred, a fervent proponent of the public domain, found the extensions hard to swallow. Joining his legal crusade was Lawrence Lessig, a law professor with a keen eye on the digital epoch's copyright intricacies. Their 2003 legal challenge did more than question the law; it illuminated a pressing debate. On one side, there were entities like Disney striving to safeguard their creations for extended periods. On the other, advocates like Eldred and Lessig argued for the societal value of a rich public domain, where culture becomes accessible and can be built upon by new generations. Their legal foray underscored this intricate dance: the push and pull between proprietary rights and the public's right to cultural inheritance.
Borrowed Brilliance: Navigating the Remix Revolution
After the disheartening loss against the CTEA, Lawrence Lessig found renewed vigor, channeling his frustrations into championing the remix culture. In his book "Remix," Lessig dove deep into the cultural bedrock, illustrating that creativity in our digital age often blossoms by iterating on existing works. This idea was further popularized and echoed in later years by Austin Kleon's musings on the art of "stealing" ideas, and the compelling narrative presented in the YouTube video, "Everything is a Remix." However, Lessig was adamant: there's a chasm between remixing, a transformative act, and piracy, a mere replication.
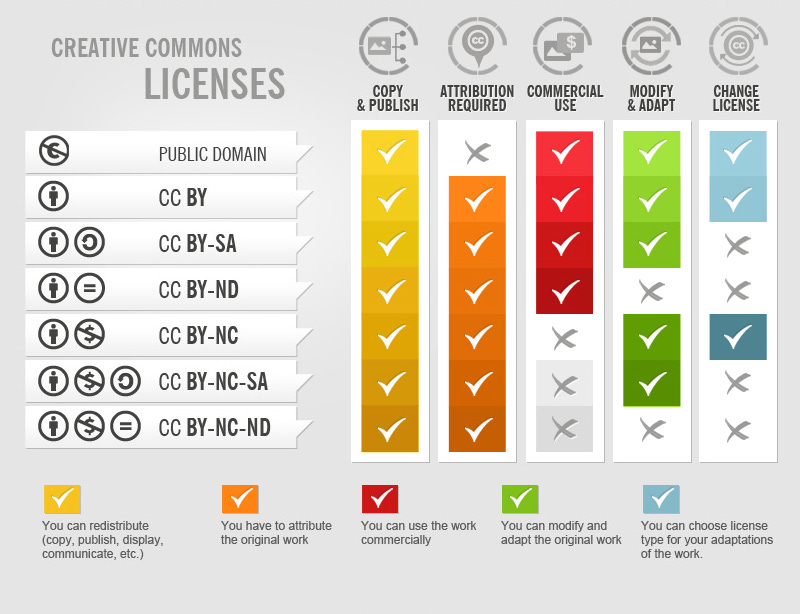
The "read/write" culture Lessig illuminated, driven by the internet's democratizing power, demanded an updated approach to copyright. As a reaction, he co-founded Creative Commons, crafting licenses that gave creators the leeway to dictate how their work could be shared and adapted. This initiative was more than just a legal workaround; it was a response to a rapidly changing digital environment where Lessig pointed out that "Code is Law."
The Digital Frontier: Traversing the Complex Terrain of Data and Derivatives
Creative Commons has been a resounding success, with over 2 billion works licensed using its model. However, the rise of artificial intelligence has led to an insatiable hunger for data to train ever-larger AI models. In the early days of AI research, models were trained on datasets like Wikipedia, which contains a respectable 6 million articles. But as models grew more complex, requiring billions or even trillions of data points, new sources of training data were desperately needed.
Enter Common Crawl - a non-profit initiative established in 2008 with the ambitious goal of crawling and indexing the entire public web. The significance of Common Crawl became clear when OpenAI revealed that a staggering 60% of the training data for its powerful GPT-3 model came from Common Crawl's repository.
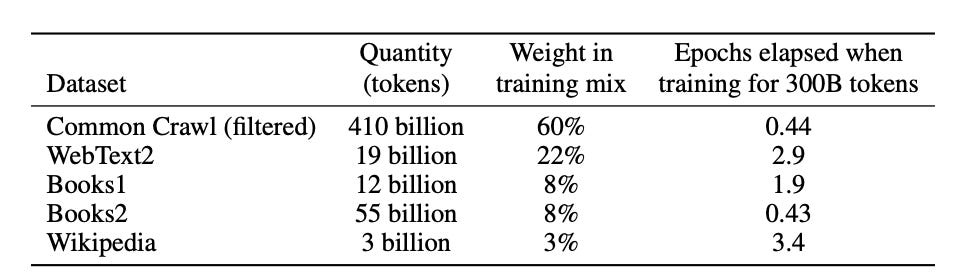
Initially, Common Crawl flew under the radar, with its data trove viewed as fair game for training AI models. However, as these models attained proficiency, concerns around copyright infringement arose. Comedian Sarah Silverman fired the opening shot, suing OpenAI for allegedly using her copyrighted material without permission. The venerable New York Times is rumored to be exploring similar legal action. Many websites have updated their terms of use, prohibiting the use of their content to train AI models.
The core issue is not simply AI models consuming copyrighted content as input. Writers like Silverman and outlets like the Times want their work consumed and learned from. The thornier question is what happens when AI models generate new content echoing or derived from copyrighted source material. With their ability to produce content at scale in uncanny mimicry of original works, AI models have thrust the complex world of copyright into uncharted territory. Resolving these tensions will shape the future landscape of creativity and authorship.
When Innovation Undercuts the Law: How Technology Outpaces Copyright
Throughout history, technological leaps have forced pivotal recalibrations of copyright law. With each creative disruption, new innovations fundamentally alter the economic realities underpinning existing legal frameworks. This pattern has repeated with the advent of various technologies:
Originally, producing book-length texts required access to scarce printing presses - an inherent barrier to mass copyright infringement. Your printer was unlikely to assist in unlawful duplication. The high costs of reproduction created economic hurdles to unauthorized copying.
The digital revolution profoundly disrupted this model. Perfectly duplicating reams of text suddenly became trivial, with copying costs effectively nil. You could now infringe copyright in the comfort of your own home using ubiquitous digital scanning and burning tools. Copyright's premise of scarce reproduction was completely upended.
Next, the internet eliminated barriers to global distribution. Copyrighted works could be freely shared worldwide through services like Napster. Physical media and post were no longer necessary. Rights holders' control over distribution faltered as digital content became instantly accessible.
Recent advances in AI, particularly large language models (LLMs), introduced unprecedented capabilities for repurposing copyrighted information. AI can now uncouple and recombine information, style, and expression from copyrighted works. This sparks thorny new questions around copyright's aim to protect specific creative expression, not underlying information.
LLMs can now ingest volumes of copyrighted material, extract key facts and styles, then synthesize entirely new works. For instance, an LLM could parse New York Times reporting, and then generate a new article combining those facts with Sarah Silverman's creative voice.
The resulting work would likely sound convincingly like something Silverman herself created. It would also closely echo the Times' factual reporting. Yet neither could likely claim infringement since no protected expression was copied, only style and bare facts.
As AI grows more skilled at parodying style and repurposing information, calls for updated copyright laws will likely grow. However, any changes must balance creative incentives with the ability to build upon facts and ideas.

Creativity Versus Control: Copyright's Neverending Tug-of-War
The core dilemma in regulating AI and copyright is the use of regulation to define and protect intellectual property in eras of technological change. This top-down approach only functions when the population is in agreement.
But inexorably, if people desire some new capability, technology evolves to enable those yearnings. Content owners can sue companies like Meta and OpenAI, but it may be too late to cram the AI genie back in the bottle. There is simply too much money and momentum propelling ever-larger models, with new datasets constantly emerging. Even if Sarah Silverman's works are scrubbed from training sets, a user could reproduce her style by prompting an open-source AI with examples.
We've seen this movie before. In 1999, 15-year-old programmer Jon Johansen reverse-engineered the encryption protecting DVDs, sharing the code online. The movie industry sued to halt the spread, even barring links to the code. But the populace disregarded the rules, soon sporting t-shirts emblazoned with the forbidden decryption. Information wants to be free, after all.

For better or worse, AI represents another inevitable genie let loose from the bottle. Copyright law always lags technology, but draconian enforcement cannot put this genie back. The path forward lies in fluid policy and compromises. If creativity is the ultimate renewable resource, the goal should be catalyzing its continued flow.
And what of Mickey Mouse, the instigator of so many copyright extensions? While the CTEA added another 20 years to his exclusivity, Mickey finally emerges into the public domain later this year.