
Beyond Nvidia: The Need for Speed Propels AI Past GPUs
How the Demand for Faster AI is Driving Innovation Beyond GPUs, Reshaping the Chip Industry, and Paving the Way for Real-Time AI Interactions


Back in November 2022, OpenAI's release of ChatGPT to the public sparked a frenzy of excitement, wonder, and no small amount of trepidation. Within days, millions were experimenting with this new technology, marveling at its ability to generate human-like text, answer questions, and even write code. But beneath the surface of this AI revolution, a less visible but equally crucial challenge emerged: the need for speed and processing power.
 | Beebom")
As users flocked to ChatGPT, they quickly encountered a familiar digital-age frustration: waiting. The pauses between queries, the overloaded servers, and delayed responses were more than just minor inconveniences. They highlighted a fundamental shift in computing requirements. Unlike traditional web software that runs efficiently on CPUs, large language models (LLMs) like ChatGPT demand the parallel processing power of GPUs (Graphics Processing Units) to function effectively.
The Rise of GPU Computing in AI
This realization kicked off a race to acquire and build GPU-powered data centers. Companies scrambled to secure these specialized chips, with Nvidia emerging as the dominant supplier. Their GPUs, originally designed for rendering video game graphics, proved ideal for the parallel processing demands of transformer-based neural networks.
The key to GPUs' success in AI lies in their memory bandwidth. While a typical CPU manages about 50GB/s, high-end GPUs can achieve a staggering 750GB/s. This capability made GPUs the workhorses of AI, powering everything from image recognition to natural language processing. Nvidia, recognizing this potential early, quickly positioned itself at the heart of the AI infrastructure. By early 2024, they commanded an 88% share of the GPU market, up from 80% just months earlier.

However, Nvidia's stronghold on the AI chip market didn't go unchallenged. As the demand for faster, more efficient AI processing grew, innovators began to question whether repurposed graphics cards were truly the optimal solution for AI workloads. This led to the emergence of a new wave of competitors, each armed with a different approach to AI computation. These newcomers weren't content with simply improving upon existing GPU technology; they aimed to change the architecture of chip.
The ASIC Revolution: Specialized Chips for AI
Enter the era of ASICs (Application-Specific Integrated Circuits) for AI. Unlike general-purpose GPUs, ASICs are custom-designed chips built for a specific task – in this case, running large language models. This specialized approach promised to deliver better performance and efficiency, potentially leapfrogging the capabilities of even the most advanced GPUs. Companies like Groq and Cerebras have embraced this ASIC philosophy, each with their own unique twist on chip design.
To understand the impact of these new technologies, it's crucial to grasp the concept of "tokens." In the context of language models, tokens are the basic units of text that the AI processes. A token can be a word, part of a word, or even a single character, depending on the model's encoding. The speed at which a model can process tokens directly affects how quickly it can generate responses, making tokens per second a key performance metric.
To understand the significance of recent advancements, let's first look at the performance of familiar large language models (LLMs). OpenAI's GPT-4, one of the most advanced models available, outputs about 107 tokens per second. Anthropic's Claude 3.5 Sonnet manages around 83 tokens per second. These speeds result in noticeable lags during interactions.
For those looking to run open-source models like Meta's Llama 8B, even high-end AI hosting companies were offering speeds of less than 300 tokens per second. This performance, while adequate for many applications, still fell short of real-time, human-like interactions.
Then Groq entered the scene. Their Language Processing Unit (LPU) achieved 750 tokens per second when running Meta's Llama 3.1 8B model, at a cost of just $0.06 per million tokens. This leap in performance promised to transform the user experience.
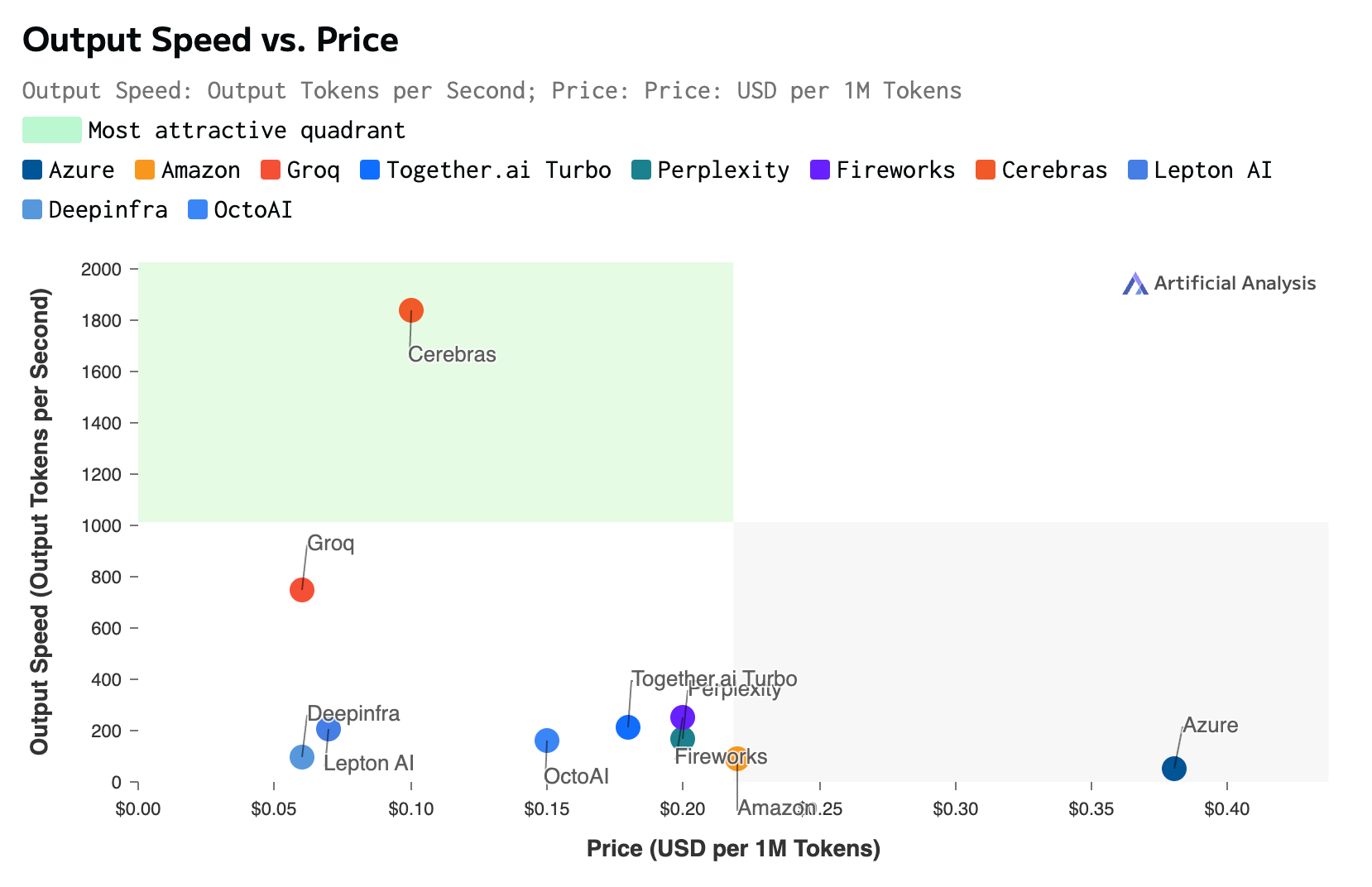
But the race for speed hasn't stopped there. This week, Cerebras announced an even more mind-bending achievement: 1,800 tokens per second at $0.10 per million tokens with their Wafer-Scale Engine (WSE). Their approach to chip design is revolutionary, integrating a staggering 44GB of SRAM onto a single, wafer-scale chip. This is orders of magnitude more on-chip memory than traditional processors, enabling incredibly fast data access and processing.

The Future of AI Interaction and Market Dynamics
These advancements don't just represent faster processing; they open the door to new applications and use cases. For AI assistants to truly integrate into our workflows, they need to operate in real-time and be interruptible – just like a human colleague. A demonstration of this potential can be seen in an application built on Cerebras' API. This demo showcases AI-driven interactions that are fluid, responsive, and capable of handling interruptions naturally, offering a glimpse into the future of human-AI collaboration.
The evolution of the AI chip market itself raises intriguing questions. It's fascinating to note that the challenge to Nvidia's dominance hasn't come from established tech giants like Intel (whose stock and market position have suffered from missing the AI shift) or Google with its TPUs. Instead, it's come from innovative startups whose first offerings are not only price-competitive but significantly raise the bar on performance.
This space continues to unfold in fun and exciting ways!